Understanding Retrieval-Augmented Generation: A Solution to LLM Hallucinations
11/11/20252 min read
Introduction to LLMs and Their Challenges
Large Language Models (LLMs) have revolutionized the field of artificial intelligence, enabling advanced conversational agents and content generation. However, a persistent issue that many users have encountered is that LLMs sometimes generate hallucinated content or reflect outdated information. This phenomenon occurs when the model synthesizes responses based on training data, which may not always include the most current events or facts. To address these limitations, researchers have introduced a technique known as retrieval-augmented generation (RAG).
What is Retrieval-Augmented Generation?
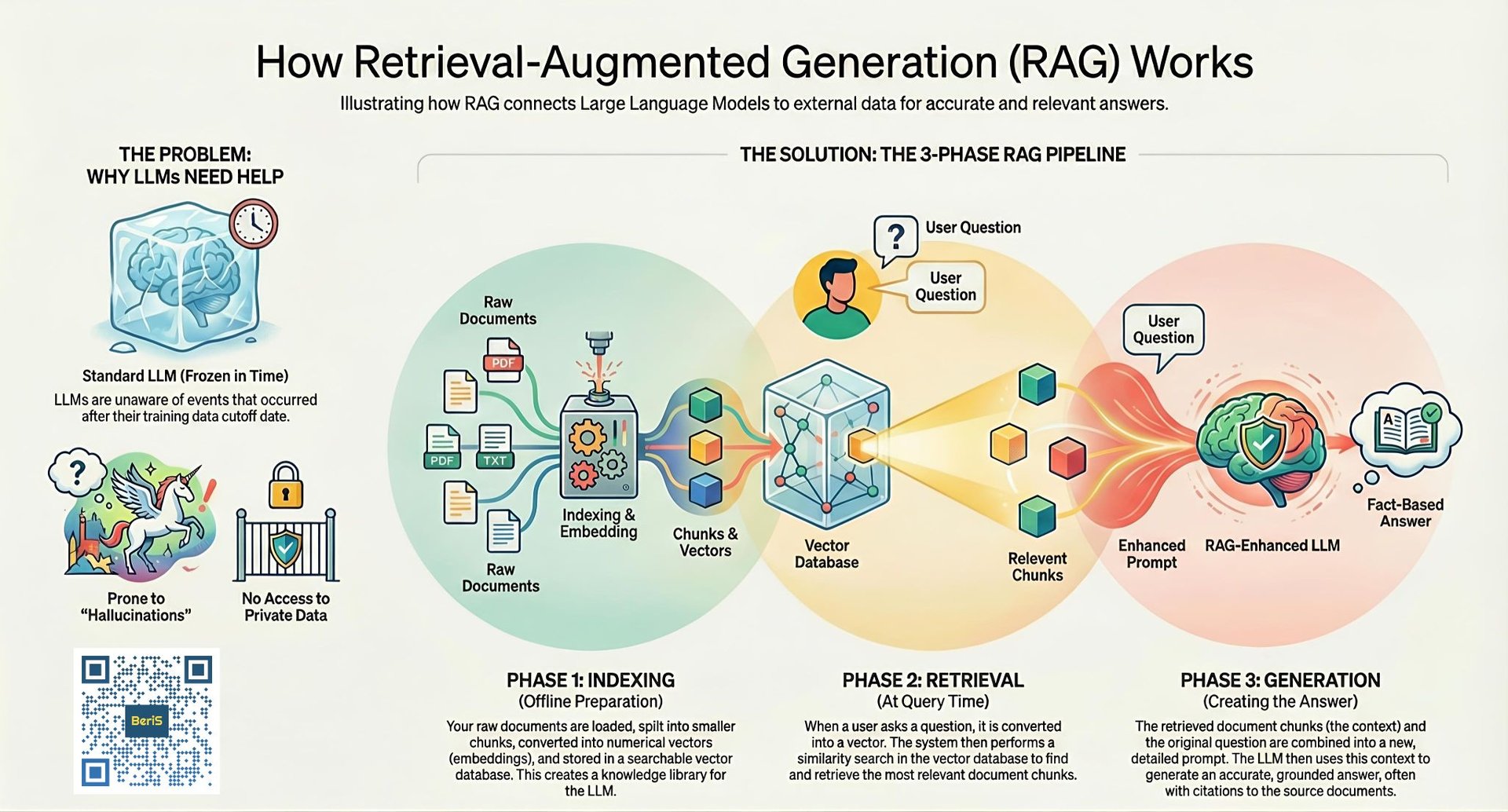
Retrieval-augmented generation is an innovative approach that combines the generation capabilities of LLMs with real-time access to external knowledge sources. The primary aim of RAG is to enhance the accuracy of outputs by grounding them in reliable, up-to-date information. This technique operates in three distinct phases, ensuring that the generated outputs are not only coherent but also factually accurate.
The Three Phases of RAG
RAG is systematically executed in three phases: indexing, retrieval, and generation. Each of these phases is crucial for the effective functioning of the model.
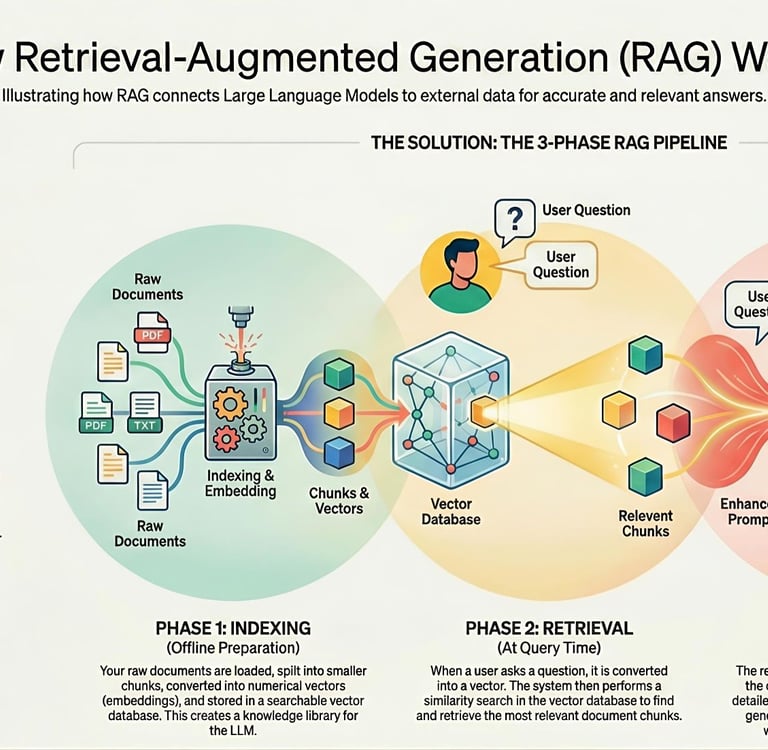
1. Indexing: In the first phase, documents containing relevant information are chunked into smaller pieces. These chunks are then embedded and stored in a vector database. This process involves transforming textual data into numerical vectors that can be more easily processed and searched.
2. Retrieval: Once the data is indexed, the next phase involves retrieving relevant information. When a user submits a query, it is converted into a vector representation. The RAG system then searches the vector database to identify the most pertinent document chunks that correspond to the vector of the query. This targeted retrieval ensures that the model focuses on the most relevant data.
3. Generation: Finally, the retrieved context is provided to the LLM, which uses this grounded information to generate an accurate and contextually relevant response. By leveraging real-time data, this stage significantly reduces the likelihood of hallucinations and enhances the overall reliability of the output.
Conclusion
In conclusion, retrieval-augmented generation represents a significant advancement in addressing the limitations faced by large language models. By integrating a robust retrieval mechanism with the generative capabilities of LLMs, RAG enhances the precision and relevance of responses. This approach not only mitigates issues of hallucination but also ensures that users receive up-to-date and trustworthy information. As AI continues to evolve, techniques like RAG will be essential for improving the reliability of conversational agents and enriching user experiences.
ADDRESS
Level 2, Vietcomreal Building
Consulting
Training
Email: info@berisolutions.com
BeriS Ltd. Co. © 2024. All rights reserved.
68 Nguyen Hue, District 1, HCMC, Viet Nam